 Object Detection Models
Object Detection Models
FCOS
Introduced by Tian et al. in FCOS: Fully Convolutional One-Stage Object DetectionFCOS is an anchor-box free, proposal free, single-stage object detection model. By eliminating the predefined set of anchor boxes, FCOS avoids computation related to anchor boxes such as calculating overlapping during training. It also avoids all hyper-parameters related to anchor boxes, which are often very sensitive to the final detection performance.
Source: FCOS: Fully Convolutional One-Stage Object Detection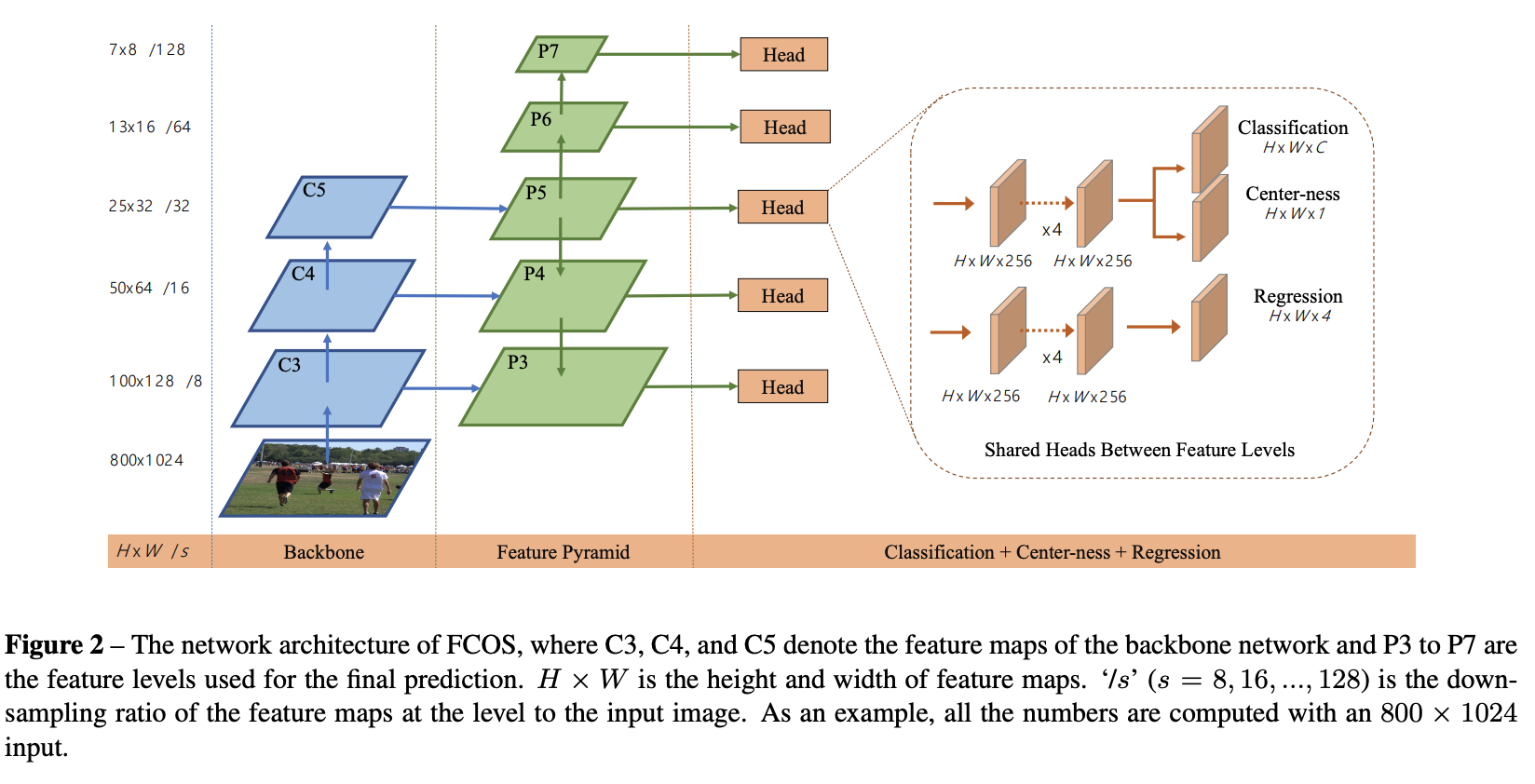
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Object Detection | 55 | 35.71% |
| Semantic Segmentation | 13 | 8.44% |
| Instance Segmentation | 12 | 7.79% |
| Pedestrian Detection | 8 | 5.19% |
| Pseudo Label | 4 | 2.60% |
| Autonomous Driving | 4 | 2.60% |
| Domain Adaptation | 3 | 1.95% |
| Pose Estimation | 3 | 1.95% |
| Decoder | 3 | 1.95% |
 FPN
FPN
 Non Maximum Suppression
Non Maximum Suppression

